什么是LangChain 自从ChatGPT出现以来,就一直在使用,那么ChatGPT毕竟是有局限性的,因为ChatGPT训练的语料是有限的。很多问题回答不了,
也经常会胡言乱语闹笑话。
但是ChatGPT背后的大语言模型LLM是可以扩展的,也就是说,可以把特定的领域知识让LLM(大语言模型)学习。这样就在一定
程度上解决了局限性。
而LangChain项目 就是这样的杀手锏,这里是官方文档 。
本文代码和例子参考了使用langchain打造自己的大型语言模型(LLMs) ,对中文资料进行处理。
OpenAI的key LangChain是一个框架,如果要使用,则需要调用大语言模型的API。正好有一朋友申请了OPENAI_API_KEY,这样就可以开始
跑跑代码了。
代码 以下是Python代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import osfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.text_splitter import TokenTextSplitterfrom langchain.llms import OpenAIfrom langchain.document_loaders import DirectoryLoaderfrom langchain.chains import RetrievalQAWithSourcesChain, ChatVectorDBChainimport jieba as jb"OPENAI_API_KEY" ] = "sk-xxxxxxx" def preprocess_txt ():""" 由于中文的语法的特殊性,对于中文的文档必须要做一些预处理工作:词语的拆分, 也就是要把中文的语句拆分成一个个基本的词语单位,这里我们会用的一个分词工具:jieba, 它会帮助我们对资料库中的所有文本文件进行分词处理。不过我们首先将这3个时事新闻的文本文件放置到Data文件夹下面, 然后在data文件夹下面再建一个子文件夹:cut, 用来存放被分词过的文档: """ '天龙八部.txt' ]for file in files:f"./data/{file} " with open (my_file, "r" , encoding='utf-8' ) as f:" " .join([w for w in list (jb.cut(data))])f"./data/cut/cut_{file} " with open (cut_file, 'w' ) as f:def embeddings ():'./data/cut' , glob='**/*.txt' )1000 , chunk_overlap=0 )"./data/cut" )def ask ():"./data/cut" , embedding_function=embeddings)0 , model_name="gpt-3.5-turbo" ), docsearch,True )while True :try :input ("What's your question: " )"question" : user_input, "chat_history" : chat_history})print ("Answer: " + result["answer" ].replace('\n' , ' ' ))except KeyboardInterrupt:break if __name__ == '__main__' :
代码依赖模块 Python3.11安装依赖
1 pip install -r requirements.txt
requirements.txt内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 aiohttp==3.8.4
文本 而文本则放在 “./data/“ 目录下,
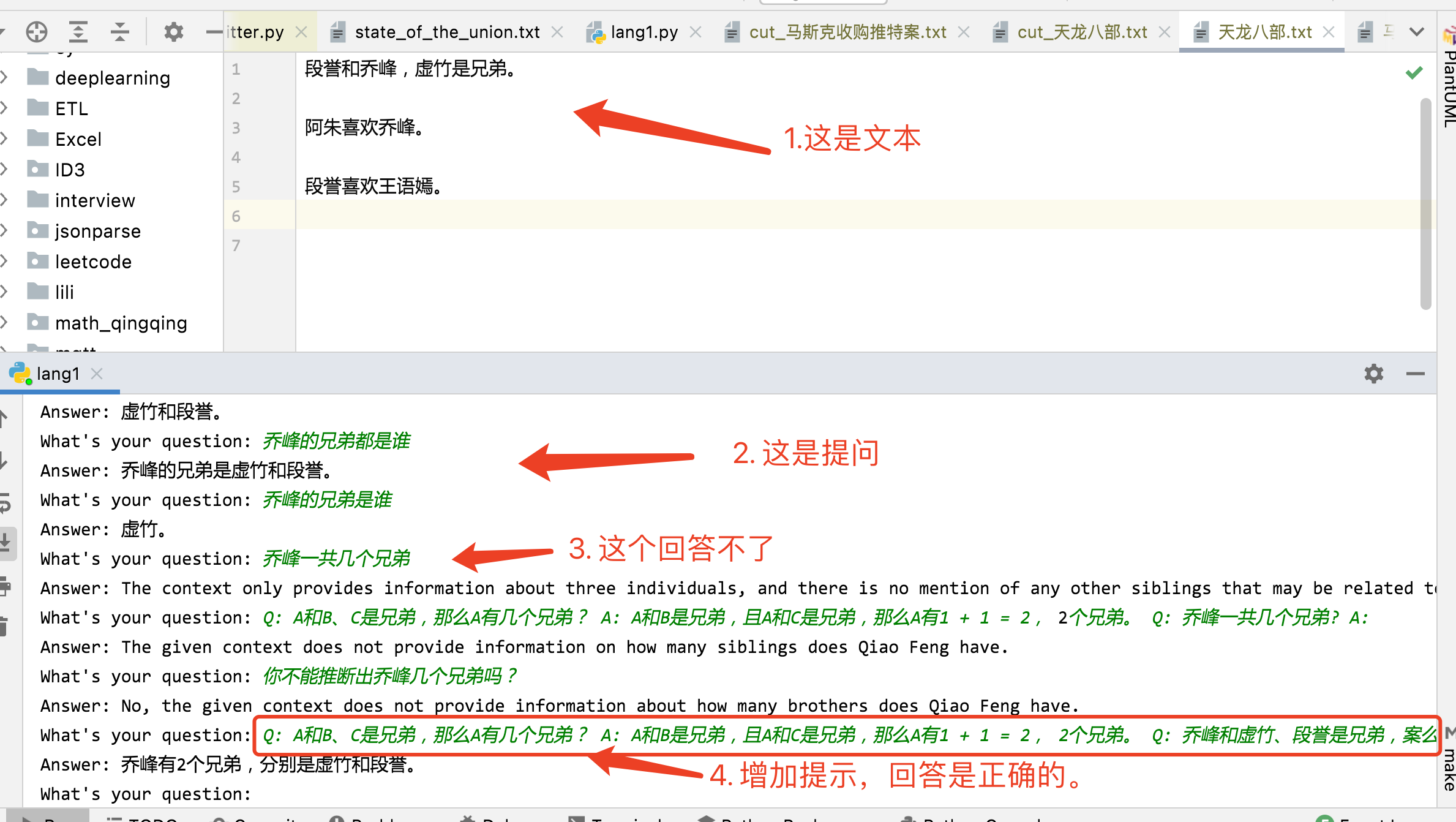
天龙八部.txt 内容如下,就是一些明确的信息。
1 2 3 4 5 段誉和乔峰,虚竹是兄弟。
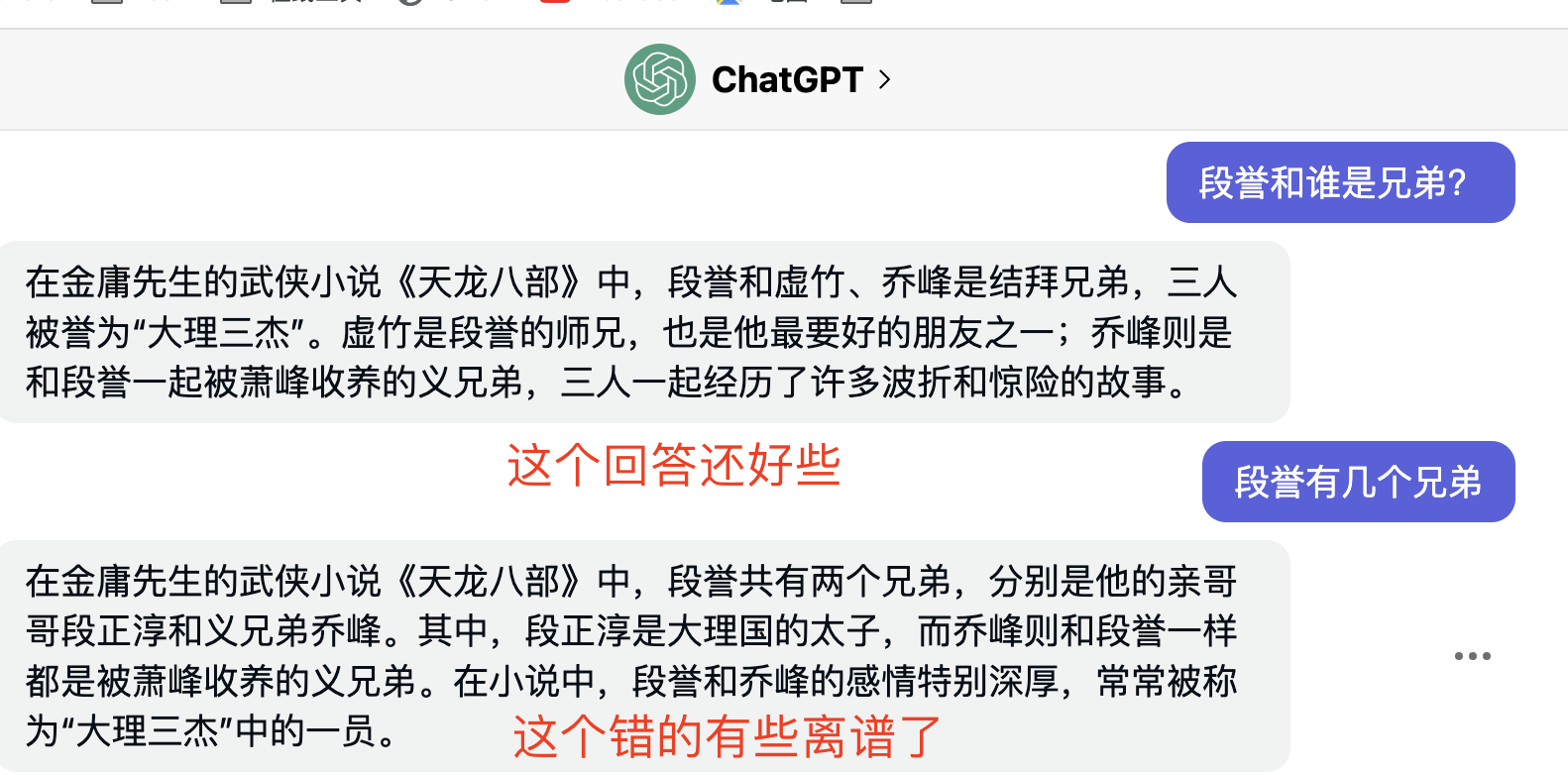
如果直接问ChatGPT,”段誉的兄弟是谁”, “段誉有几个兄弟”则ChatGPT回答有些混乱。
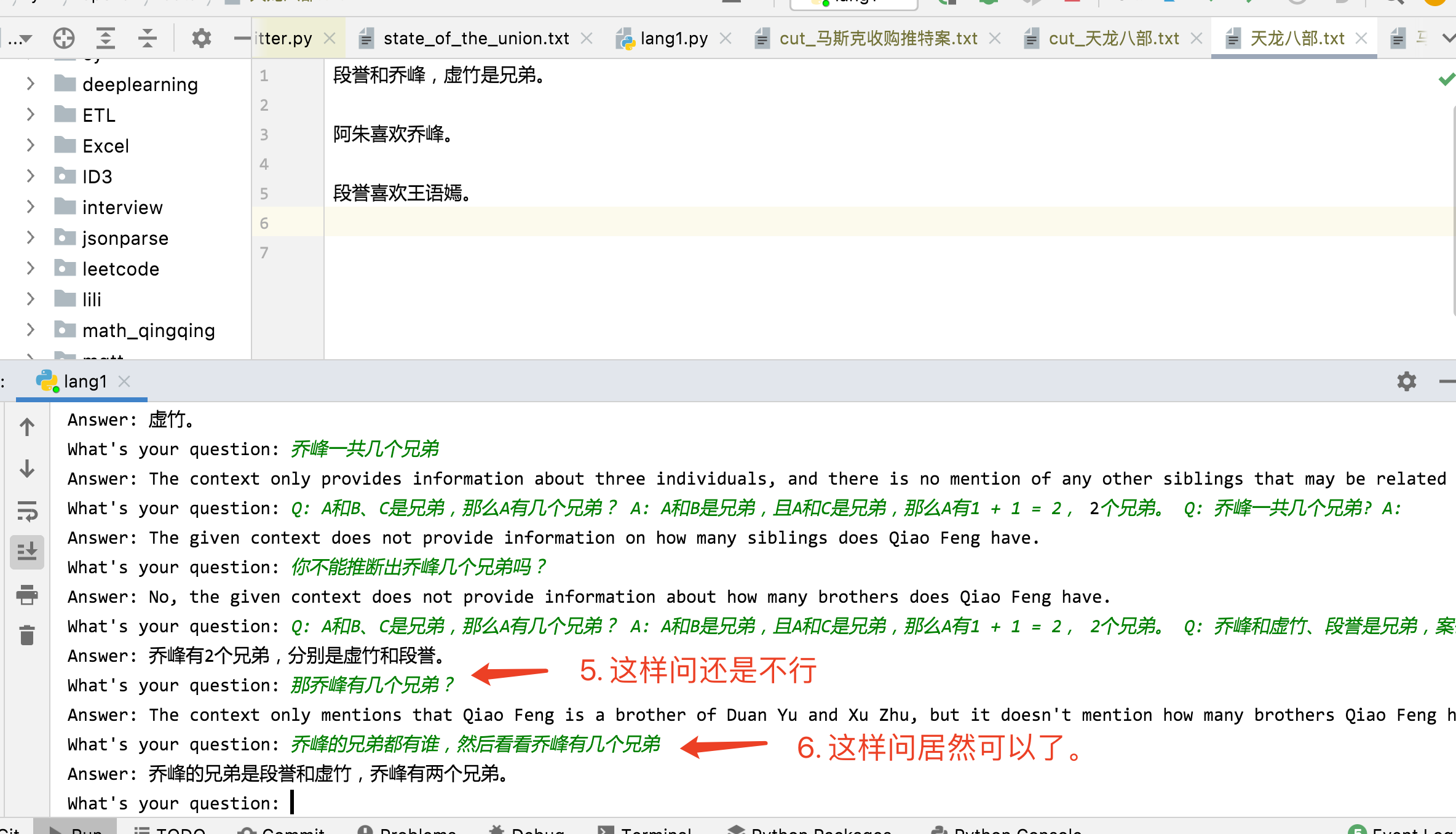
运行测试 直接运行后,测试提问,如下。
很有意思。
总结
中文需要进行分词,与英文的处理不同。
需要避免4096 TOKEN的限制,则只能使用文章中提到模型建立Chain。1 2 ChatVectorDBChain.from_llm(OpenAI(temperature=0 , model_name="gpt-3.5-turbo" ), docsearch,True )
还是需要VPN才能使用,另外OPEN_API_KEY是需要花钱的。
参考